
1. 인덱스 특징과 종류
- 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 찾아보기와 유사한 개념
- 테이블을 기반으로 선택적으로 생성 할 수 있는 구조 (생성하지 않아도 되고 여러 개를 생성해도 됨)
- 인덱스의 기본적인 목적은 검색 성능의 최적화
- insert, update, delete 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경해야 하기 때문에 오히려 느려질 수 있는 단점 존재
가. 트리 기반 인덱스
- DBMS에서 가장 일반적인 인덱스는 B-트리 인덱스
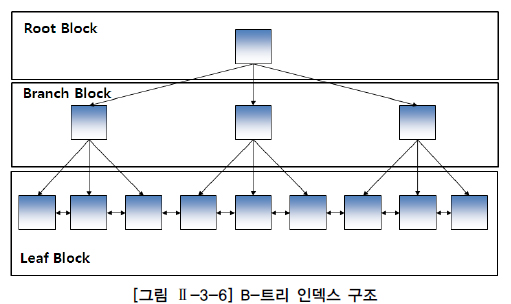
- B-트리 인덱스는 브랜치 블록(Branch Block)과 리프 블록(Left Block)으로 구성
- 루트 블록(Root Block) : 가장 상위 블록
- 브랜치 블록 : 분기를 목적으로 하는 블록, 다음 단계의 블록을 가리키는 포인터를 가지고 있음
- 리프 블록 : 트리의 가장 아래 단계에 존재, 인덱스를 구성하는 컬럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Identifier/Rowid)로 구성
- 인덱스 데이터는 인덱스를 구성하는 컬럼의 값으로 정렬 (만약, 인덱스 데이터의 값이 동일하면 레코드 식별자 순서로 저장)
- 리프 블록은 양뱡향 링크(Double Link)를 가지고 있는데 이것을 통해서 오름 차순과 내림차순 검색을 쉽게 할 수 있음.
- B-트리 인덱스는 '='로 검색하는 일치(Exact Mathch) 검색과 'BETWEEN', '>'등과 같은 연산자로 검색하는 범위(Range) 검색 모두에 적합한 구조
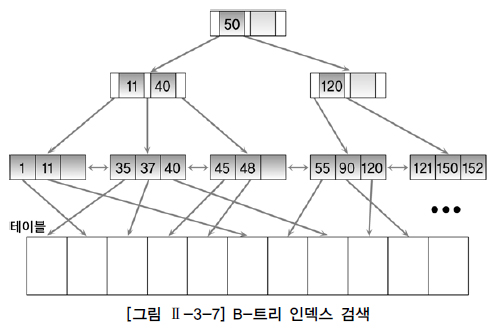
1단계. 브랜치 블록의 가장 왼쪽 값이 찾고자 하는 값보다 작거나 같으면 왼쪽 포인터로 이동
2단계. 찾고자 하는 값이 브랜치 블록의 값 사이에 존재하면 가운데 포인터로 이동
3단계. 오른쪽에 있는 값보다 크면 오른쪽 포인터로 이동
- 블록을 찾을 때까지 위 3단계 과정을 반복 > 리프 블록에서 찾고자 하는 값이 존재하면 해당 값을 찾은 것이고, 존재하지 않으면 검색에 실패
ex1. 위 그림 2-3-7에서 37을 찾는다는 전재
루트 블록에서 50보다 작으므로 왼쪽 포인터로 이동 > 37은 왼쪽 브랜치 블록의 11과 40 사이의 값이므로 가운데 포인터로 이동 > 이동한 결과 해당 블록이 리프 블록이므로 37이 블록 내에 존재하는지 검색
ex2. 위 그림에서 37과 50 사이의 모든 값을 찾는다는 전재(between 37 and 50)
리프 블록에서 37을 찾고 50보다 큰 값을 만날 때까지 오른쪽으로 이동하면서 인덱스를 읽음
- 인덱스 데이터가 정렬되어 있고 리프 블록이 양방향 링크로 연결되어 있기 때문에 가능
- 인덱스를 경유해서 반환된 결과 데이터는 인덱스 데이터와 동일한 순서로 갖게 되는 특징이 있음
- 인덱스를 생성할 때 동일 컬럼으로 구성된 인덱스를 중복해서 생성할 수 없음
- 인덱스 구성 컬럼은 동일하지만 컬럼의 순서가 다르면 별도의 인덱스를 생성할 수 있음 (job+sal / sal+job 컬럼 순서의 인덱스를 별도의 인덱스로 생성 가능)
- 인덱스의 컬럼 순서는 질의 성능에 중요한 영향을 미침
- 그 외 비트맵 인덱스, 리버스 키 인덱스, 함수기반 인덱스가 오라클 트리 기반 인덱스에 존재함
나. SQL Server의 클러스터형 인덱스
- 저장 구조에 따라 클러스터형(clustered) 인덱스와 비클러스터형(nonclustered) 인덱스로 나뉨.
- 책에서는 클러스터형 인덱스에 대해서만 설명
- 클러스터형 인덱스의 중요한 특징
첫째, 인덱스의 리프 페이지가 곧 데이터 페이지
- 테이블 탐색에 필요한 레코드 식별자가 리프 페이지에 없음. (인덱스 키 컬럼과 나머지 컬럼을 리프 페이지에 같이 저장하기 때문에 테이블에 랜덤 액세스 할 필요가 없음(
- 클러스터형 인덱스의 리프 페이지를 탐색하면 해당 테이블의 모든 컬럼 값을 곧바로 얻을 수 있음.
- 클러스터형 인덱스를 사전에 비유할 수 있음. ( 영한 사전은 알파벳 순으로 정렬되어 각 단어 바로 옆에 한글 설명이 붙어 있음 . 전문서적 끝 부분에 있는 찾아보기(=색인)가 페이지 번호만 알려주는 것과 비교하면 차이점을 알 수 있음)
둘째. 리프 페이지의 모든 로우(=데이터)는 인덱스 키 컬럼 순으로 물리적으로 정렬되어 저장
- 데이터 로우는 물리적으로 한 가지 순서로만 정렬될 수 있음.
- 클러스터형 인덱스는 테이블당 한개만 생성 가능(전화번호부 한 권을 상호와 인명으로 동시에 정렬할 수 없는 것과 마찬가지)
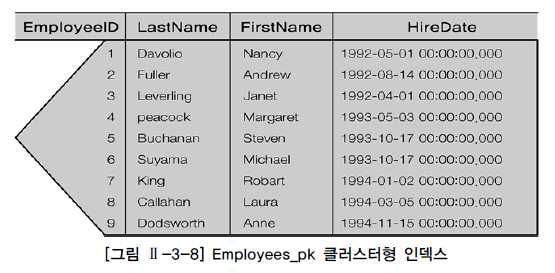
▲ EmployeeID, LastName, FirstName, Hire Date로 구성된 Employees 테이블에 대해 Employee ID에 기반한 클러스터형 인덱스를 생성한 모습
리프 블록에 인덱스 키 컬럼 외에도 테이블의 나머지 컬럼이 모두 함께 있음.
참고: http://www.dbguide.net/db.db?cmd=view&boardUid=148209&boardConfigUid=9&categoryUid=216&boardIdx=136&boardStep=1
'DBMS > SQL_최적화' 카테고리의 다른 글
| SQL 최적화 기본 원리] 옵티마이저와 실행계획 (0) | 2018.01.01 |
|---|

댓글